如何解决AI/ML训练中负载不均问题?包转发还是流转发?
引言
在AI/ML训练中,单个GPU与其他GPU同步训练数据时,通常发送多少个活动IP流?
答案是只有一个。而且流量以满接口速率发送,目前是400Gbps。
现在以太网架构,最常用的负载均衡方式是根据流负载均衡。这种方式在GPU训练场景(流数量少、流量大),很容易导致哈希冲突,最终导致链路负载不均。
两个流哈希冲突,导致链路传输时间翻倍,如果有更多的流冲突,情况会进一步恶化,最终增加整体AI/ML训练完成时间。下图展示了典型哈希冲突导致的网络拥塞。
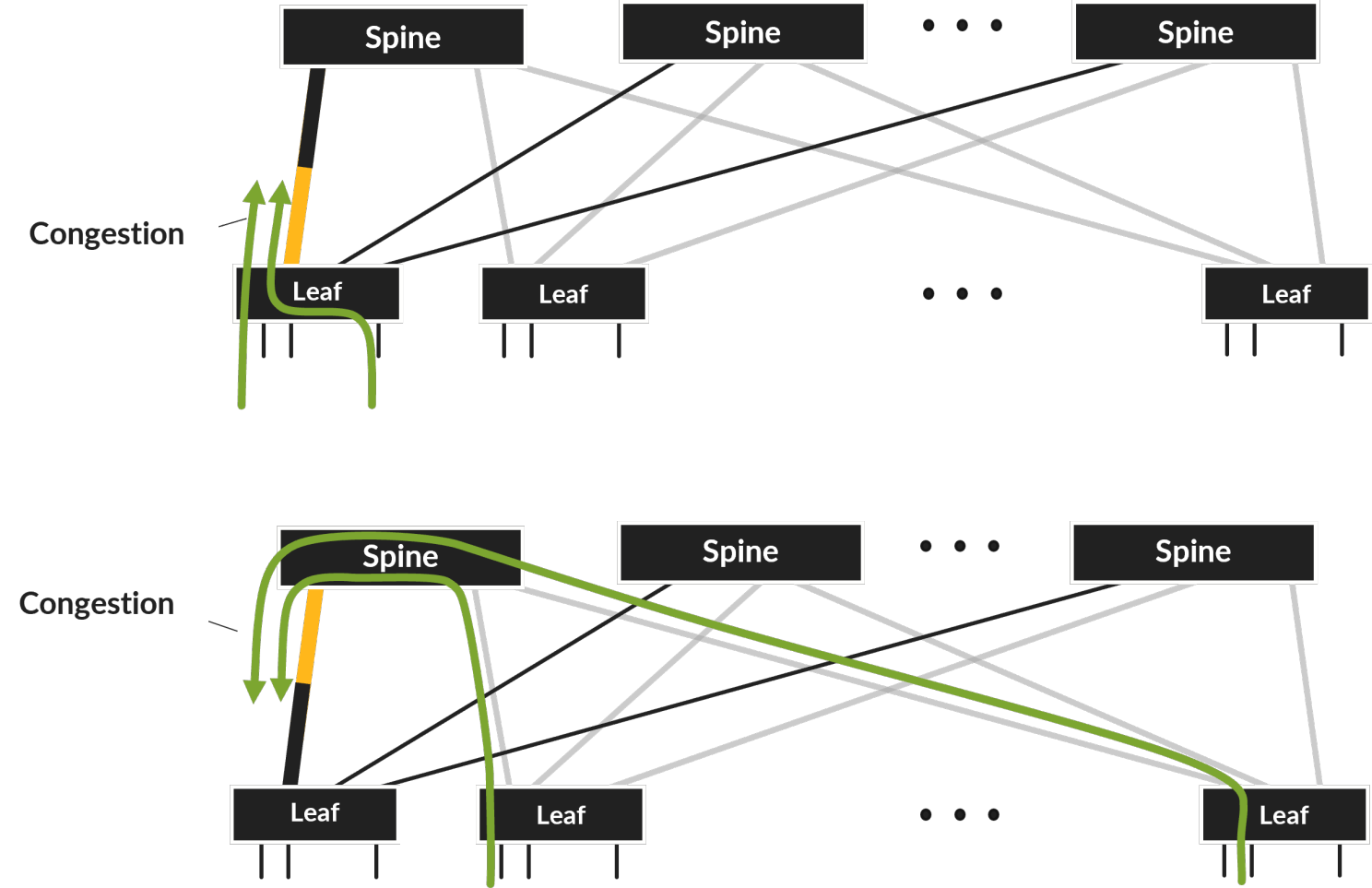
网络设备供应商提出了各种解决上述流量拥塞的方案,如Broadcom的动态负载均衡/全局负载均衡、Juniper的自适应负载均衡等。
各大供应商提出了基于数据包或cell的喷洒方案,以解决流量少而大导致的链路负载不均问题。
然后,这些方案,需要在链路的端侧或叶子节点进行数据包重排,这种重排需要昂贵的缓存,相关的调度器结构复杂度也会增加,最终导致需要更多的芯片面积,这对于大规模网络(数以万计的端口)来说,具有成本、端口密度和功耗的问题。
那么,有更好的选择吗?
可以说,数据包喷洒是迄今最好的方案,其可以非常高效地利用并行路径。
但是,能否避免引入昂贵的数据包重排呢?
为了回答这个问题,我们首先需要研究下GPU的工作负载。
GPU工作负载
首先需要研究下开源的Nvidia Collective Communications Library (NCCL),重点关注InfiniBand / RoCEv2传输。
GPU之间发送了什么,将数据从一个GPU的内存传输到另一个GPU的内存?
从技术上讲,AI训练不在乎数据以哪种顺序写入内存:无论是最后一个字节优先传输到内存中,还是第一个字节传输到内存中,只要所有字节都传输完成后,应用程序就可以正常运行。
从应用视角看,整个传输流程,如下图所示:应用程序启动传输或接收完成通知,网卡则使用RDMA从内存中提取数据或写入数据到GPU内存。
应用程序本身不需要按顺序传递数据包,但必须在传输完成后得到通知。
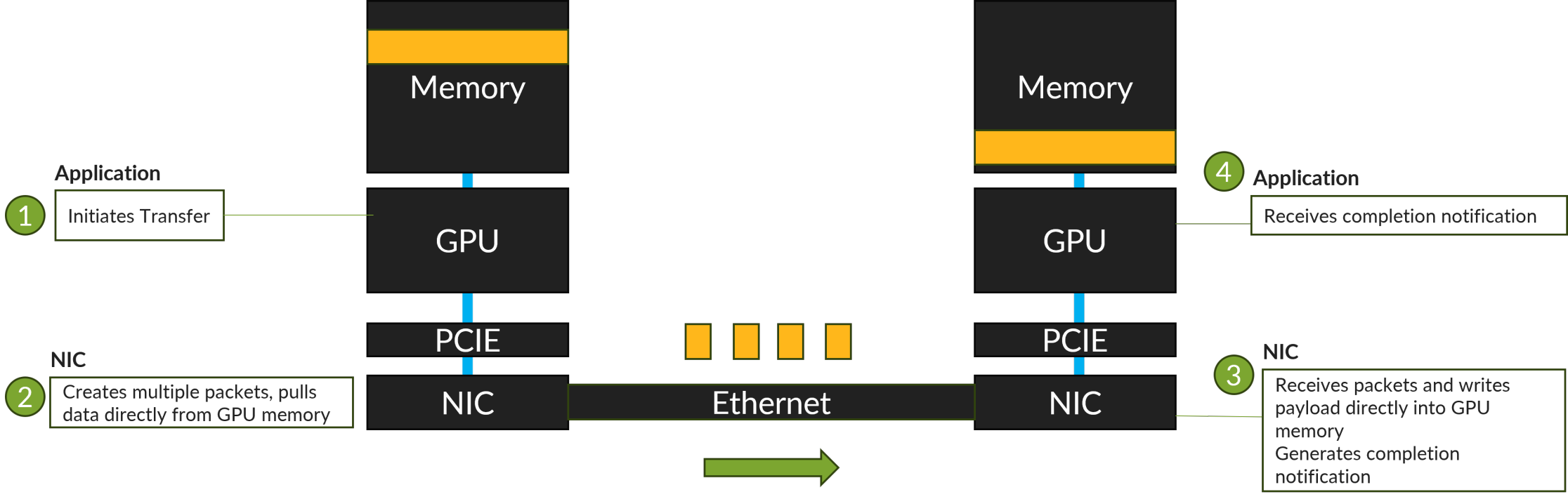
具体如何工作的?
NCCL使用InfiniBand可靠连接传输服务,该服务是面向连接的,发送者确认了数据包的传输,数据包在传输过程中严格保序。
为此,RoCEv2规范明确要求将连接映射到单个IP流,这就是为什么我们有一个低熵问题。
解决低熵问题
我们能否改变标准,并修改传输语义以实现无序传输?
事实上,根据大量学术研究者、工程师的努力,我们已经可以找到一些解决方案,如 Revisiting Network Support for RDMA-SIGCOMM2018。
但在新标准建立之前,可以使用实现了精细乱序接收与重排逻辑的网卡,如Nvidia Connect-X 5 及以上版本 。
具体来说,NCCL 使用两种不同的 InfiniBand “verbs” 操作进行传输:
- RDMA_WRITE - 从源内存传输到目的内存,事务从源发起。
- RDMA_WRITE_WITH_IMM - 与上述相同,但还通过所谓的“Immediate Data”通知目的地传输完成。该操作用于序列中的最后一个内存传输事务。
远程内存写操作支持最多传输2GB的数据。实际传输发生在小于或等于最大传输单元(通常为4KB)的较小片段中。
通常,传输分为4种不同类型的片段(数据包):
- RDMA WRITE First - 第一个片段,包含RDMA 扩展传输头,其中包含远程内存地址和数据长度。头部后面是数据有效负载。网卡将地址信息存储在其本地,并在随后的片段中使用它。
- RDMA WRITE Middle - 中间片段,只包含数据有效负载。
- RDMA Write Last - 传输的最后一个片段,只包含数据有效负载。
- RDMA Write Last with Immediate - 传输的最后一个片段,包含数据有效负载和 immediate data。
网卡不支持上述数据包的乱序接收,如果先收到中间片段,网卡必须将该数据包保留在网卡内存中,直到收到第一个片段 - 网卡必须存储数兆字节的数据在网卡上, 消耗昂贵缓存,这显然是不可行的。
Nvidia 的 Connect X 5 网卡在启用 Nvidia 自适应路由或启用丢包加速时会以如下方式解决网卡昂贵缓存的消耗问题。
Connect X 5 网卡将每个 RDMA WRITE 请求都映射到一个或多个相同类型的 RDMA 操作:RDMA WRITE Only。该操作在每个数据包中嵌入了 RDMA 扩展传输头,这使得网卡可以在接收到任何数据包后直接将数据写入 GPU 内存,并在网卡内存中携带最少的额外状态以检测数据包丢失。
Fabric 端到端解决方案示意图如下所示。
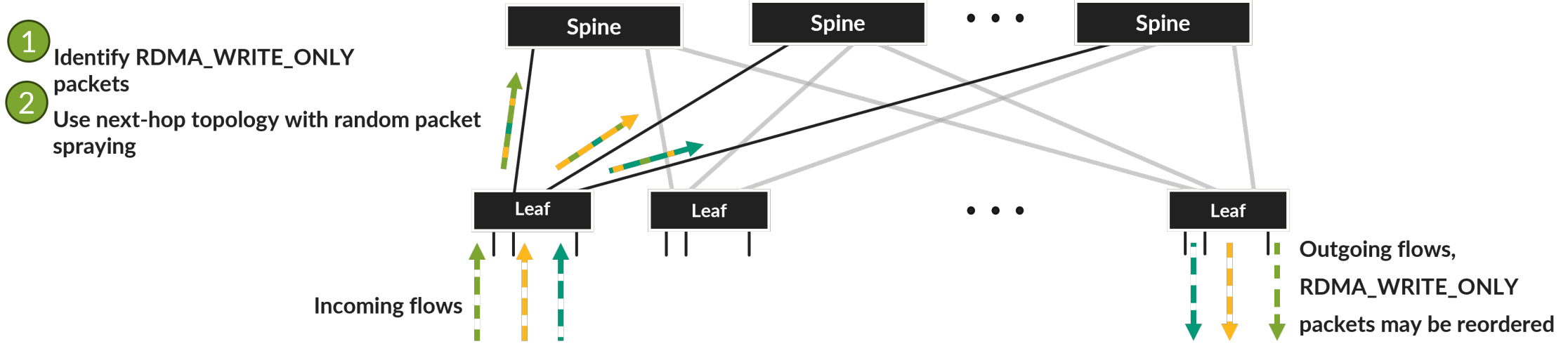
值得注意的是,Nvidia 网卡对于 RDMA_WRITE 实现了这种行为,但对于 RDMA_WRITE_WITH_IMM 则没有。
这就是为什么 NCCL 还有一个特殊的设置来启用自适应路由(默认情况下在以太网传输中禁用)。在这种操作模式下,如果数据长度超过一定限制,NCCL 使用 RDMA_WRITE 操作传输数据负载,然后用长度为零的 RDMA_WRITE_WITH_IMM 发送传输完成通知。网卡负责将通知按顺序传递给接收应用程序。
结论
在AI/ML训练场景,可以修改集合通信库与网卡,通过每包携带RDMA 扩展传输头(包含远程内存地址和数据长度),实现低成本的网卡乱序接受。当然,我们需要一个支持这种RDMA数据包喷射的以太网传输层。
可以预见,这种简单的喷射技术很难被超越,其他解决方案如调整流量转向路径以避开拥塞路径,以及以太网传输层的内部重新排序,在不久的将来可能会失去动力,并最终消失。
评论