RDMA协议详解
RDMA,即 Remote Direct Memory Access,是一种绕过远程主机 OS kernel 访问其内存中数据的技术,概念源自于 DMA 技术。在 DMA 技术中,外部设备(PCIe 设备)能够绕过 CPU 直接访问 host memory;而 RDMA 则是指外部设备能够绕过 CPU,不仅可以访问本地主机的内存,还能够访问另一台主机上的用户态内存。由于不经过操作系统,不仅节省了大量 CPU 资源,同样也提高了系统吞吐量、降低了系统的网络通信延迟,在高性能计算和深度学习训练中得到了广泛的应用。本文将介绍 RDMA 的架构与原理,详解介绍其协议。
技术背景
传统的 TCP/IP 网络通信,数据需要通过用户空间发送到远程机器的用户空间,在这个过程中需要经历若干次内存拷贝:

- 数据发送方需要将数据从用户空间 Buffer 复制到内核空间的 Socket Buffer
- 数据发送方要在内核空间中添加数据包头,进行数据封装
- 数据从内核空间的 Socket Buffer 复制到 NIC Buffer 进行网络传输
- 数据接受方接收到从远程机器发送的数据包后,要将数据包从 NIC Buffer 中复制到内核空间的 Socket Buffer
- 经过一系列的多层网络协议进行数据包的解析工作,解析后的数据从内核空间的 Socket Buffer 被复制到用户空间 Buffer
- 这个时候再进行系统上下文切换,用户应用程序才被调用
在高速网络条件下,传统的 TPC/IP 网络在主机侧数据移动和复制操作带来的高开销限制了可以在机器之间发送的带宽。
HPC/AI/ML 应用场景需要更快和更轻量级的网络通信,消除传统网络通信带给计算任务的瓶颈,由此提出了RDMA技术。
RDMA利用 Kernel Bypass 和 Zero Copy技术提供了低延迟的特性,同时减少了CPU占用,减少了内存带宽瓶颈,提供了很高的带宽利用率。RDMA提供了基于 IO 的通道,这种通道允许一个应用程序通过RDMA设备对远程的虚拟内存进行直接的读写。
RDMA 技术有以下几个特点:
- CPU Offload:无需CPU干预,应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- Kernel Bypass:RDMA 提供一个专有的 Verbs interface 而不是传统的TCP/IP Socket interface。应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换
- Zero Copy:每个应用程序都能直接访问集群中的设备的虚拟内存,这意味着应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下,数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
下面是 RDMA 整体框架架构图,从图中可以看出,RDMA在应用程序用户空间,提供了一系列 Verbs 接口操作RDMA硬件。RDMA绕过内核直接从用户空间访问RDMA 网卡。RNIC网卡中包括 Cached Page Table Entry,用来将虚拟页面映射到相应的物理页面。

现在,RDMA技术已经成为高性能计算、云计算、存储系统和分布式数据库等领域的重要组成部分。标准化的RDMA技术包括InfiniBand、RoCE(RDMA over Converged Ethernet)、iWARP,并得到了广泛的商业支持和采用。发展历史简述如下:
-
1999年,IB行业联盟(InfiniBand Trade Association,IBTA)成立。
-
2000年,发布了第一版的InfiniBand标准。
-
2002年,在IB第一个版本发布两年后,成立RDMA联盟,作为IETF的补充。
-
2007年,提出基于TCP/IP的RDMA, iWARP。
-
2010年,InfiniBand Trade Association定义了RoCE v1(RDMA over Converged Ethernet,发音为“rocky”)
-
2014年,提出更完整的版本RoCE v2,并支持路由功能。
值得注意的是,InfiniBand(IB)、RoCE(RDMA over Converged Ethernet)和iWARP(Internet Wide Area RDMA Protocol)标准是由不同的组织发布的。
-
IB、RoCE v2由InfiniBand Trade Association(IBTA)组织负责发布和维护。IBTA是一个由多家公司组成的行业联盟,致力于推动和促进InfiniBand技术的发展和标准化。
-
iWARP是一种将RDMA技术扩展到传统TCP/IP网络上的协议,由Internet Engineering Task Force(IETF)发布和维护。iWARP最早是由RDMA Consortium组织负责协议标准的制定,并在完成RDMA 规范1.0版本之后转交给你IETF RDDP工作组进行后续的标准化工作。
时间回退到二十世纪末,随着 CPU 性能的迅猛发展,早在 1992 年 Intel 提出的 PCI 技术已经满足不了人民群众日益增长的 I/O 需求,I/O 系统的性能已经成为制约服务器性能的主要矛盾。尽管在 1998 年,IBM 联合 HP 、Compaq 提出了 PCI-X 作为 PCI 技术的扩展升级,将通信带宽提升到 1066 MB/sec,人们认为 PCI-X 仍然无法满足高性能服务器性能的要求,要求构建下一代 I/O 架构的呼声此起彼伏。
经过一系列角逐,1999年,Infiniband 融合了当时两个竞争者的设计 Future I/O 和 Next Generation I/O,建立了 Infiniband 行业联盟,即 IBTA (InfiniBand Trade Association)。
当时,IBTA联合了各大厂商 Compaq、Dell、HP、IBM、Intel、Microsoft 和 Sun参与。InfiniBand 被视为替换 PCI 架构的下一代 I/O 架构,并在 2000 年发布了 1.0 版本的 Infiniband 架构 Specification,2001 年 Mellanox 公司推出了支持 10 Gbit/s 通信速率的设备。
然而好景不长,2000 年互联网泡沫被戳破,人们对于是否要投资技术上如此跨越的技术产生犹豫。Intel 转而宣布要开发自己的 PCIe 架构,微软也停止了 IB 的开发。
尽管如此,Sun 和 日立等公司仍然坚持对 InfiniBand 技术的研发,并由于其强大的性能优势逐渐在集群互联、存储系统、超级计算机内部互联等场景得到广泛应用,其软件协议栈也得到标准化,Linux 也添加了对于 Infiniband 的支持。
进入2010年代,随着大数据和人工智能的爆发,InfiniBand 的应用场景从原来的超算等场景逐步扩散,得到了更加广泛的应用。
随着主要玩家之一 QLogic,在2012年 被 Intel 收购,InfiniBand 市场领导者 Mellanox ,2020年被 NVIDIA 收购。IB逐渐进入GPU互联、AI大模型互联场景。
RDMA 协议
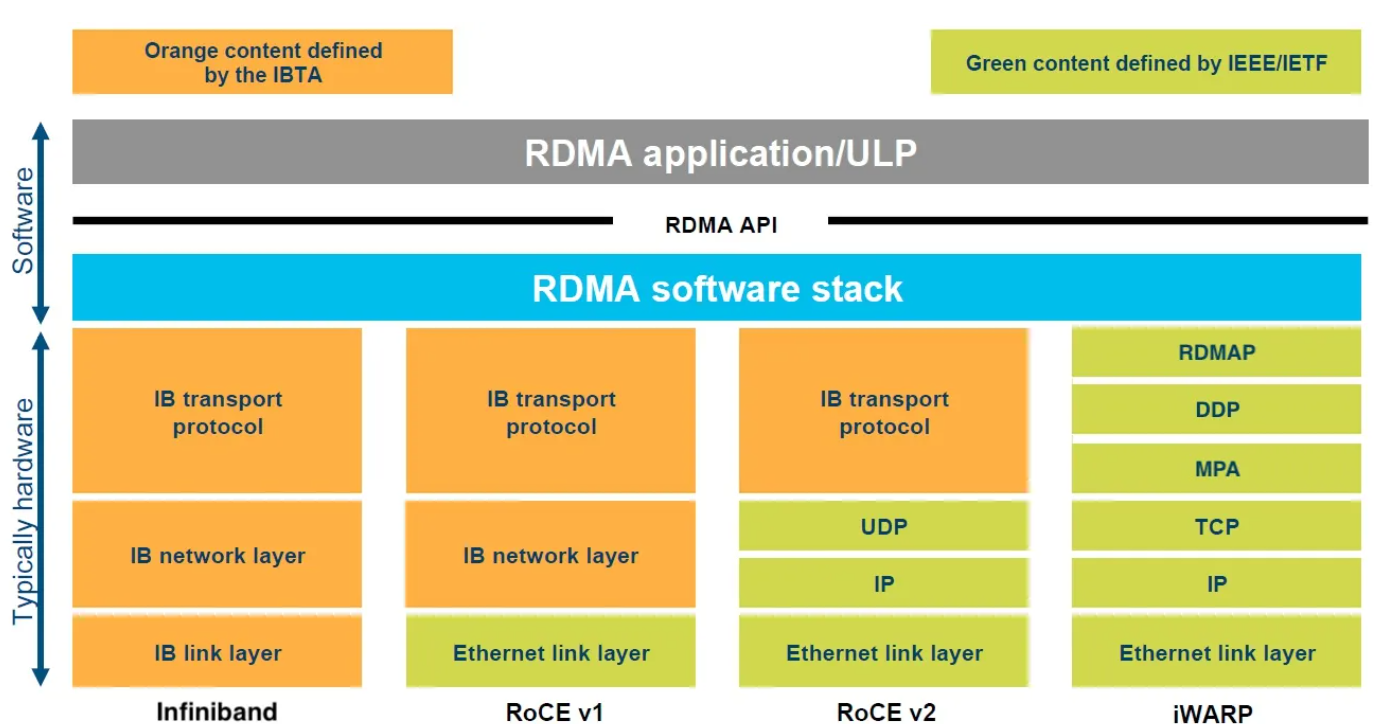
目前,RDMA有三种不同的协议实现,不同的实现对上,使用同一套编程API,对下有着不同的物理层和链路层:
- **Infiniband:**基于 InfiniBand 架构的 RDMA 技术,由 IBTA(InfiniBand Trade Association)提出。搭建基于 IB 技术的 RDMA 网络需要专用的 IB 网卡和 IB 交换机。从性能上,很明显Infiniband网络最好,但IB网卡和交换机价格也很高,然而RoCEv2和iWARP仅需使用特殊的网卡就可以了,价格相对便宜。
- **iWARP:**Internet Wide Area RDMA Protocal,基于 TCP/IP 协议的 RDMA 技术,由 IETF 定义。iWARP 支持在标准以太网基础设施上使用 RDMA 技术,而不需要交换机支持无损以太网传输,但服务器需要使用支持iWARP 的网卡。与此同时,受 TCP 影响,性能稍差。
- **RoCE v1/v2:**基于以太网的 RDMA 技术,也是由 IBTA 提出,有两个版本RoCE v1与RoCE v2。现在主要使用的是RoCE v2。RoCE支持在标准以太网基础设施上使用RDMA技术,但是需要交换机支持无损以太网传输,需要服务器使用 RoCE 网卡,性能与 IB 相当。

IB 网络架构
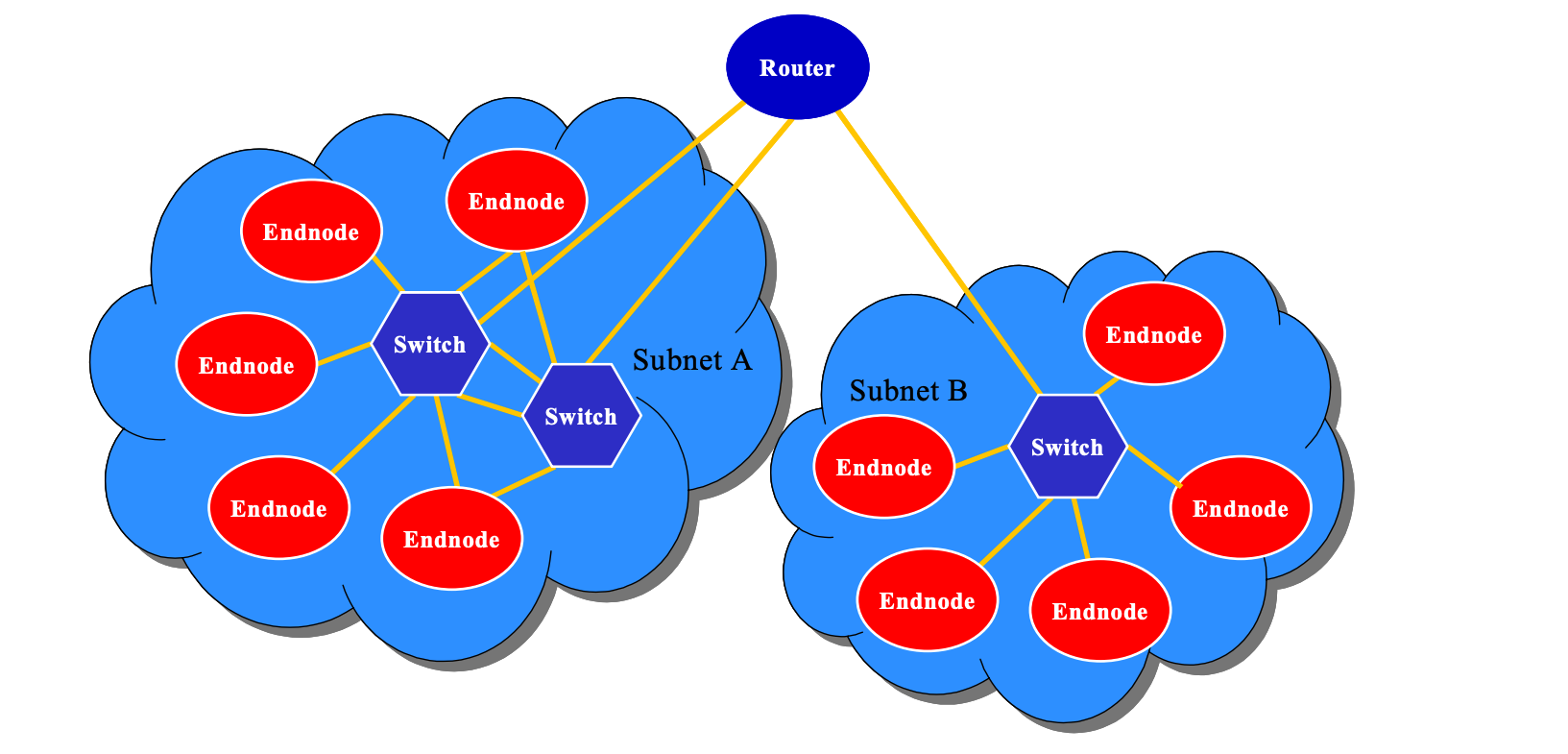
InfiniBand 架构为系统通信定义了多种实体:
- Channel Adapter(CA): 通道适配器连接InfiniBand与其他设备。通道适配器分为两种类型,主机通道适配器(HCA)和目标通道适配器(TCA)。
- Switch:IB交换机,将数据包从一个端口转发到另一个端口。
- Router:IB路由器,将数据包从一个子网转发到另一个子网。
- Subnet Manager:负责管理和维护 InfiniBand 子网的配置和操作。它的主要职责是为网络中的所有设备(例如主机、交换机和存储设备)分配必要的地址,并且配置路径以便设备之间能够进行通信。
IB提供了一种基于通道的点对点消息队列转发模型,每个应用都可通过创建的虚拟通道直接获取本应用的数据消息,无需其他操作系统及协议栈的介入。
在一个子网中,每个节点必须有一个 Channel Adapter(CA),以及一个 Subnet Manager 来管理链路。

IB通道适配器(Channel Adapters)
InfiniBand (IB) 架构中的 Channel Adapters 是连接到 InfiniBand 网络的端点设备,负责管理通信和数据传输。
有两种类型的 Channel Adapters:Host Channel Adapters (HCA) 和 Target Channel Adapters (TCA)。
-
Host Channel Adapters (HCA): HCA 主要安装在服务器或工作站中,它们处理主机端的所有 InfiniBand 协议相关的任务。HCA 负责数据打包、消息队列处理、直接内存访问 (DMA) 操作以及其他任何与网络通信相关的工作。这些适配器通常以 PCI Express (PCIe) 卡的形式存在,并提供一种或多种外部连接以与 InfiniBand 交换机或其他设备连接。IB HCA一般形态为IB网卡。
-
Target Channel Adapters (TCA): TCA 通常用于存储设备或其他特定类型的IO设备。它们的功能与 HCA 类似,但是通常针对与存储或其他特定IO类型的数据传输相关的操作进行了优化。一般支持的操作是HCA支持操作的子集。
值得注意的是,在 InfiniBand (IB) 网络中,Host Channel Adapter (HCA) 和 Target Channel Adapter (TCA) 的概念是关于通信终端类型而不是数据流动的方向。主机通道适配器(HCA)用于服务器,和目标通道适配器(TCA)用于外设,使IO设备脱离主机而直接置于网络中。
IB通道适配器是 InfiniBand 网络中的关键组件,实现物理层,链路层,网络层和传输层的功能,提供高速、低延迟的连接。2023年,NVIDIA主要两款HCA:
- NVIDIA BlueField-3 DPU :借助 400Gb/s 以太网或 NDR 400Gb/s InfiniBand 网络连接,BlueField-3 DPU 可以卸载、 加速和隔离软件定义的网络、存储、安全和管理功能,从而显著提高数据中心的性能、 效率和安全性。
- BlueField-3 SuperNIC: 专用于满足网络密集型大规模并行计算的需求,可在 GPU 服务器之间通过融合以太网提供高达 400Gb/s 的远程直接内存访问 (RDMA) 连接,从而优化 AI 工作负载峰值效率。
IB 交换机 (IB Switch)
IB交换机(Switch)包括多个端口,用于连接CA,Router或其它Switch。通过Layer 2 Local Route Header(LRH)中的LID进行转发。是IB结构中的基本组件,负责在IB子网里转发报文。
IB 交换机在 InfiniBand 网络中的作用是建立和维护高速、低延迟的数据通路。例如,NVIDIA Quantum-2 InfiniBand 交换机可提供海量吞吐、出色的网络计算能力、智能加速引擎、杰出的灵活性和健壮架构,在高性能计算 (HPC)、AI 和超大规模云基础设施中发挥出色性能,并为用户降低成本和系统复杂性。
IB 路由器(IB Router)
Router 根据 L3 中的 GRH,负责将 数据包从一个子网转发到另一个子网,当被转到到另一子网时,Router 会重建数据包中的 LID。
例如,NVIDIA SB7880 InfiniBand 路由器支持在不同的子网之间实现隔离和互通,最多支持 6 个 InfiniBand 子网。该路由器基于 Switch-IB 2 芯片,可提供 36 个高度灵活的 100Gb/s 端口。在每个子网内可以独立使用不同的网络拓扑结构,以更大限度地提高应用程序性能。
IB子网管理器(Subnet Manager,SM)
IB子网管理器(Subnet Manager,SM)负责配置本地子网,主要工作有:
- 发现子网的物理拓扑
- 给子网中的每个端口分配 LIC 和其他属性(如活动MTU、活动速度)
- 给子网交换机配置转发表
- 检测拓扑变化(如子网中节点的增删)
- 处理子网中的各种错误
SM可以驻留在子网中的任何设备中,但通常运行在服务器中。
IB 分层协议
InfiniBand 有着自己的协议栈,从上到下分为4层:传输层、网络层、数据链路层和物理层:

IB 物理层
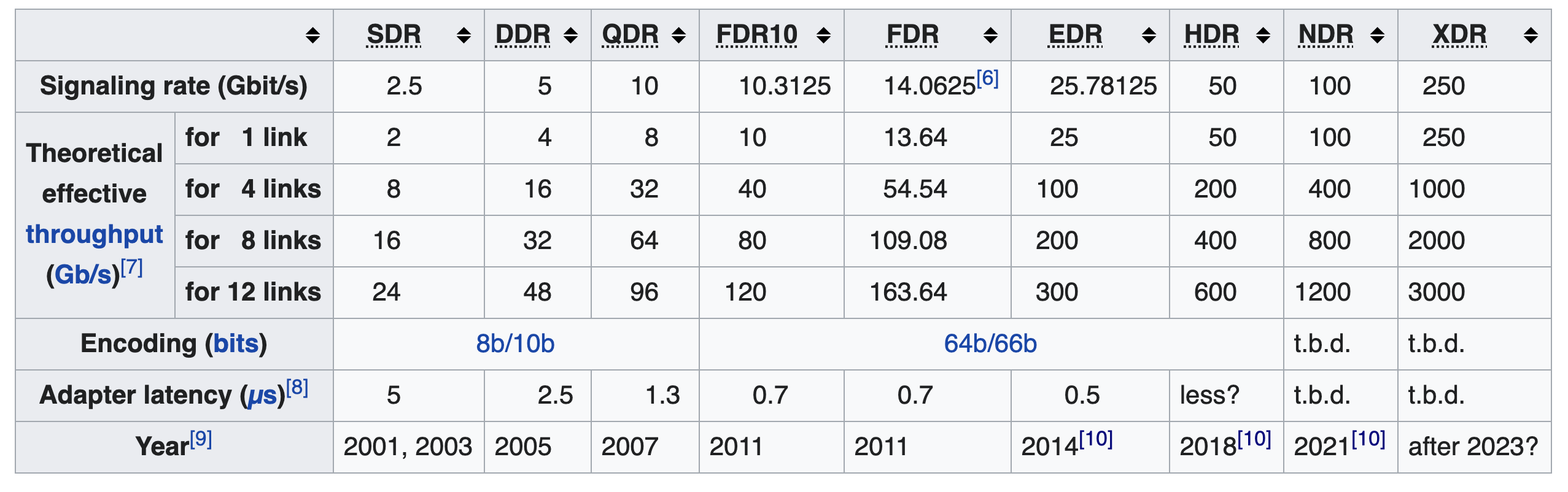
IB物理层定义了 InfiniBand 具有的电气和机械特性,InfiniBand 支持光纤和铜作为传输介质。在物理层支持不同的链路速度,每个链路由四根线组成(每个方向两条),Link 可以聚合以提高速率,目前绝大多数的系统采用 4 Link。

以 QDR(Quad Data Rate,指的是一种数据传输技术,它能够在每个时钟周期传输四个数据单位) 为例,线上的 Signalling Rate 为 10 Gb/s,由于采用 8b/10b 编码,实际有效带宽单链路为 10 Gb/s * 8/10 = 8 Gb/s,如果是 4 链路,则带宽可以达到 32 Gb/s。因为是双向的,所以 4 链路全双工的速率可以达到 64 Gb/s。
IB 链路层
链路层是 InfiniBand 架构的核心,包含以下部分:
- 数据包类型:链路层由两种类型的数据包,业务报文与管理报文,数据包最大可以为 4KB,数据包传输的类型包括两种类型
- Memory:RDMA read/write,atomic 操作
- Channel:send/receive,多播传输
- 转发:在子网中,数据包的转发和交换是在链路层完成
- 一个子网内的每个设备有一个由 Subnet Manager分配的 16 bits Local ID (LID)
- 每个数据报文中有一个 Local Route Header (LRH) 指定了要发送的目标 LID
- 在一个子网中通过 LID 来寻址
- QoS:链路层提供了 QoS 保证,不需要数据缓冲
- 虚拟通道(Virtual Lanes,VL):一种在一条物理链路上创建多条虚拟链路的机制。虚拟通道表示端口的一组用于收发数据包的缓冲区。支持的 VL 数是端口的一个属性。
- 每个 Link 支持 15 个标准的 VL 和一个用于管理的 VL15,VL15 具有最高等级,VL0 具有最低等级
- 服务等级(Service Lanes):InfiniBand 支持多达 16 个服务等级,但是并没有指定每个等级的策略。InfiniBand 通过将 SL 和 VL 映射支持 QoS
- 基于信用的流量控制(Credit Based Flow Control)
- 数据完整性:链路层通过数据报文中的 CRC 字段来进行数据完整性校验,其组成包括 ICRC 和 VCRC。
IB链路层协议格式如下所示:

其中,Local ID是在同一个子网下,设备端口的编号,类似于Ethernet的MAC地址。分配给端口的LID是由SM分配的16位值。这意味着有64K个LID可分配给子网端口,LID整体地址范围细分如下:
- 0x0000不能被使用;
- 0x0001—0xBFFF(48K)作为单播地址,单播包不会运往多个Port;
- 0xC000—0xFFFE(16K)作为多播地址,多播包会前往多个目的地;
- 0xFFFF作为可选的 LID PLID,有特殊用途;
IB 网络层
IB网络层负责将数据包从一个子网路由到另一个子网:
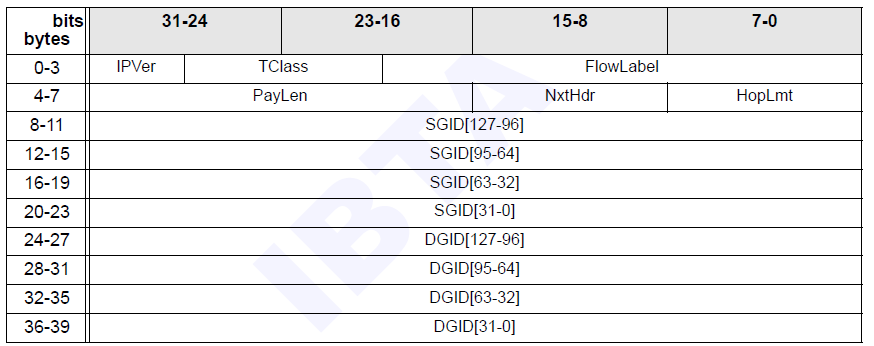
- 在子网间传输的数据包都有一个 Gloabl Route Header (GRH)。在这个 Header 中包括了该数据包的128 bit 的源 IPv6 地址和目的 IPv6 地址
- 每个设备都有一个全局的 UID (GUID),路由器通过每个数据包的 GUID 来实现在不同子网间的转发
下面是 GRH 报头的格式,长40字节,可选,用于组播数据包以及需要穿越多个子网的数据包。它使用 GID 描述了源端口和目标端口,其格式与 IPv6 报头相同。
IB传输层
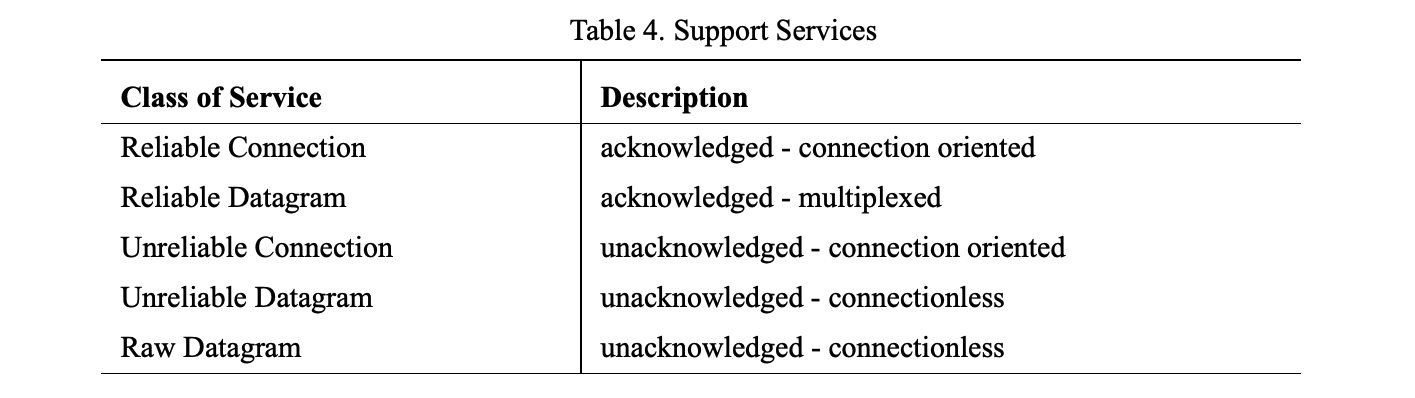
传输层负责数据包的按序传输、根据 MTU 分段和很多传输层的服务(reliable connection, reliable datagram, unreliable connection, unreliable datagram, raw datagram)。InfiniBand 的传输层所有的函数都是在硬件中实现,其性能获得巨大提升。IB支持的服务如下所示:
按照连接和可靠两个标准,可以划分出下图四种不同的传输模式:
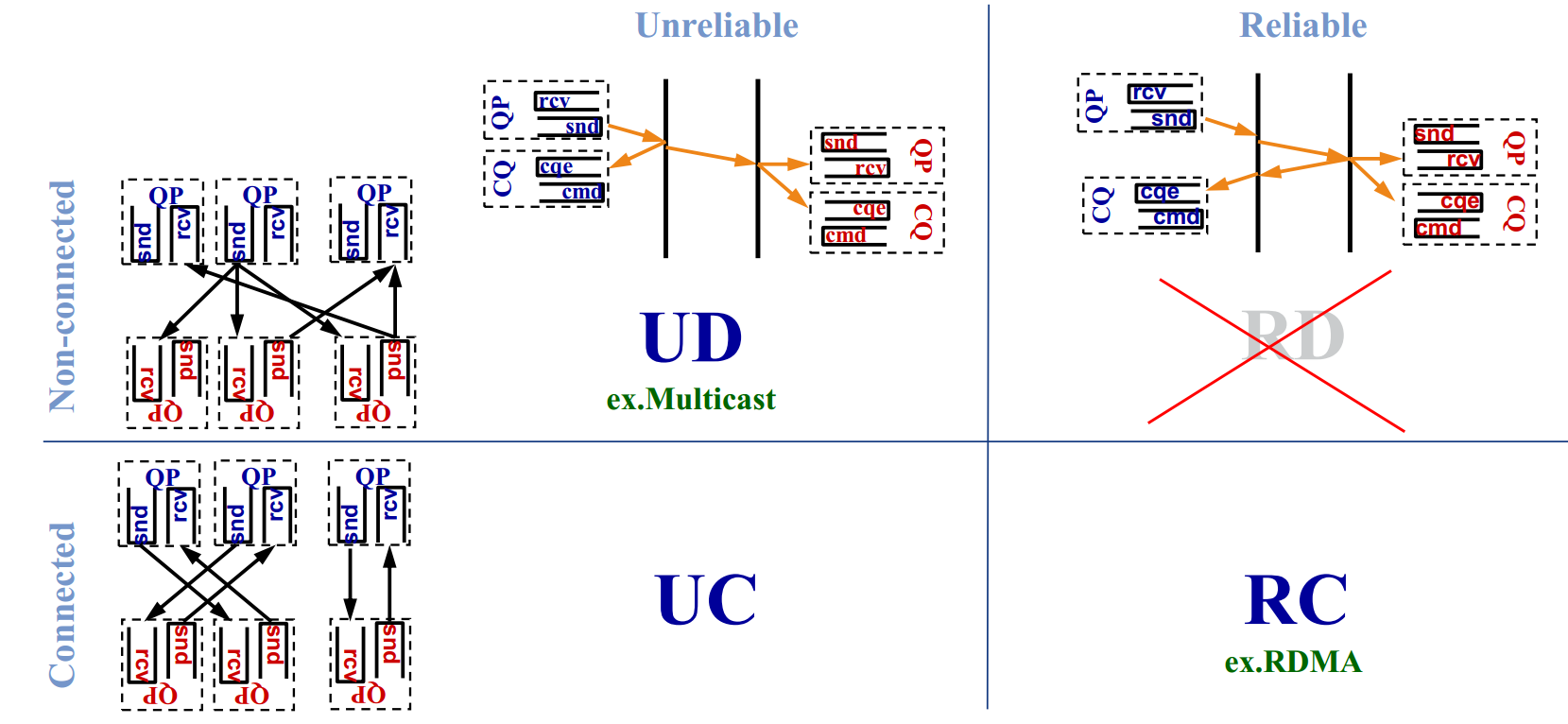
- 可靠连接(RC):一个QP只和另一个QP相连,消息通过一个QP的发送队列可靠地传输到另一个QP的接收队列。数据包按序交付,RC连接很类似于TCP连接。
- 不可靠连接(UC):一个QP只和另一个QP相连,连接是不可靠的,所以数据包可能有丢失。传输层出错的消息不会进行重传,错误处理必须由高层的协议来进行。
- 不可靠数据报(UD):一个 QP 可以和其它任意的 UD QP 进行数据传输和单包数据的接收。不保证按序性和交付性。交付的数据包可能被接收端丢弃。支持多播消息(一对多),UD连接很类似于UDP连接。
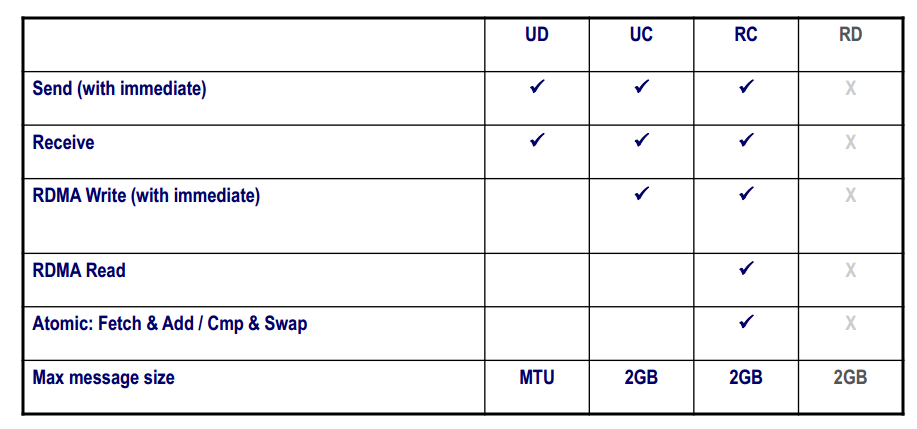
每种模式中可用的操作如下表所示,目前的RDMA硬件提供一种数据报传输:不可靠的数据报(UD),并且不支持memory verbs。
下面是传输层的 Base Transport Header 的结构,长度为 12 字节,指定了源 QP 和 目标 QP、操作、数据包序列号和分区。
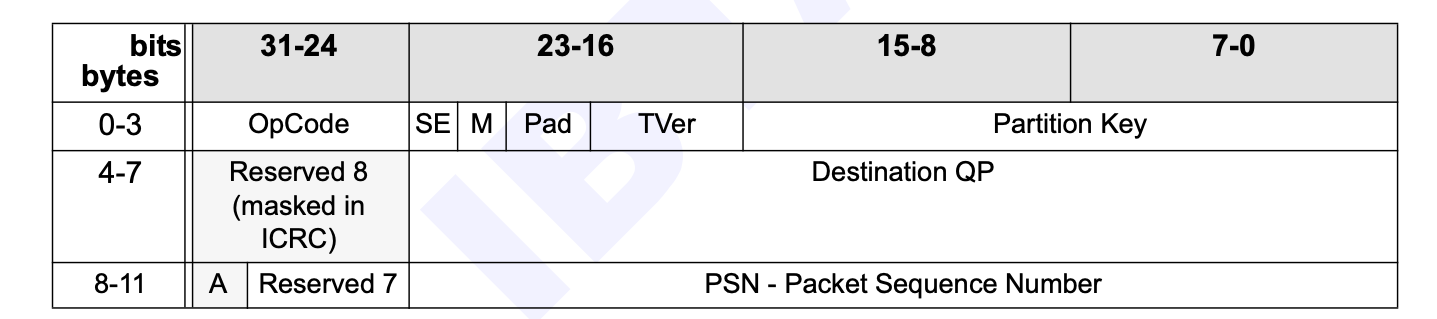
- Partition Key:InfiniBand 中每个端口 Device 都有一个由 SM 配置
P_Key表,每个 QP 都与这个表中的一个P_Key索引相关联。只有当两个 QP 相关联的P_Key键值相同时,它们才能互相收发数据包。 - Destination QP:24 bit 的目标 QP ID。
根据传输层的服务类别和操作,有不定长度的扩展传输报头(Extended Transport Header,ETH),比如下面是进行时候的 ETH:
下面是 RDMA ETH,面向于 RDMA 操作:

下面是 Datagram ETH,面向与 UD 和 RD 类型的服务:

- Queue Key:仅当两个不可靠 QP 的 Q_Key 相同时,它们才能接受对方的单播或组播消息,用于授权访问目标 QP 的 Queue。
- Source QP:24 bit 的source QP ID,用于回复数据包的Destination QP
下面是 Reliable Datagram ETH,面向于 RC 类型的服务,其中有 End2End Context 字段:

RoCE 协议
InfiniBand 架构获得了极好的性能,但是其不仅要求在服务器上安装专门的 InfiniBand 网卡,还需要专门的交换机硬件,成本十分昂贵。而在企业界大量部署的是以太网络,为了复用现有的以太网,同时获得 InfiniBand 强大的性能,IBTA 组织推出了 RoCE(RDMA over Converged Ethernet)。RoCE 支持在以太网上承载 IB 协议,实现 RDMA over Ethernet,这样一来,仅需要在服务器上安装支持 RoCE 的网卡,而在交换机和路由器仍然使用标准的以太网基础设施。网络侧需要支持无损以太网络:这是由于 IB 的丢包处理机制中,任意一个报文的丢失都会造成大量的重传,严重影响数据传输性能。
RoCE 与 InfiniBand 技术有相同的软件应用层及传输控制层,仅网络层及以太网链路层存在差异,如下图所示:
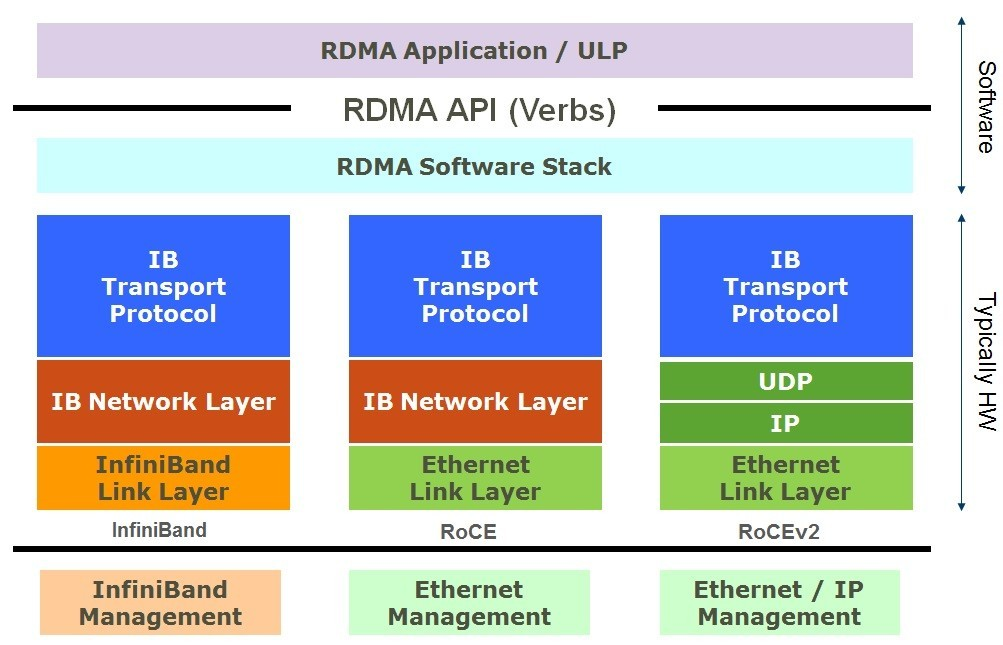
RoCE 协议分为两个版本:
- **RoCE v1协议:**基于以太网承载 RDMA,只能部署于二层网络,它的报文结构是在原有的 IB 架构的报文上增加二层以太网的报文头,通过 Ethertype
0x8915标识 RoCE 报文。 - **RoCE v2协议:**基于 UDP/IP 协议承载 RDMA,可部署于三层网络,它的报文结构是在原有的 IB 架构的报文上增加 UDP 头、IP 头和二层以太网报文头,通过 UDP 目的端口号 4791 标 识 RoCE 报文。RoCE v2 支持基于源端口号 hash,采用 ECMP 实现负载分担,提高了网络的利用率。
iWARP 协议
iWARP是一种计算机网络协议,它实现了远程直接内存访问(RDMA),可在Internet协议网络上实现高效的数据传输。它是一套由RDMAP、DDP和MPA组成的协议,可以在TCP、SCTP或其他传输协议之上进行分层。一些人声称iWARP是“Internet Wide Area RDMA Protocol”的缩写。这是不正确和误导性的,因为iWARP设计用于广泛的环境,包括局域网(LANs)、存储网络、数据中心网络、广域网(WANs)等。iWARP不是一个缩写。
Infiniband协议诞生以来,虽然相比传统以太网有着很大的优势,但是受限于从以太网切换的成本过于高昂,后面又分别产生了基于TCP的iWARP和基于UDP的RoCE v1/v2两种RDMA协议,使得RDMA的使用者只需要更换网卡,而不用更换现有的路由、交换设备以及线缆就可以享受到RDMA带来的网络性能提升和CPU负载的下降等收益。
跟RoCE协议继承自Infiniband不同,iWARP本身不是直接从Infiniband发展而来的。IB和RoCE协议都是基于《Infiniband Architecture Specification》所指定的标准的,也就是我们常说的”IB规范“。而iWARP自成一派,遵循着一套IETF设计的协议标准。
虽然遵循着不同的标准,但是iWARP的设计思想明显受到了很多Infiniband的影响,并且目前也在使用同一套软件API,也就是Verbs。
iWARP协议一共有3层,所以更准确地讲iWARP应该是一组协议的统称,或者称为协议族。下图中绿色背景的部分,即为iWARP的三层协议,IETF也将这三层称为RDDP。图中ULP指的是Upper Layer Protocol,即上层协议,iWARP通过Verbs接口向上层提供服务。ULP可以是一些存储协议,比如iSCSI、可能是中间件,比如UCX、也可能是用户的应用程序。
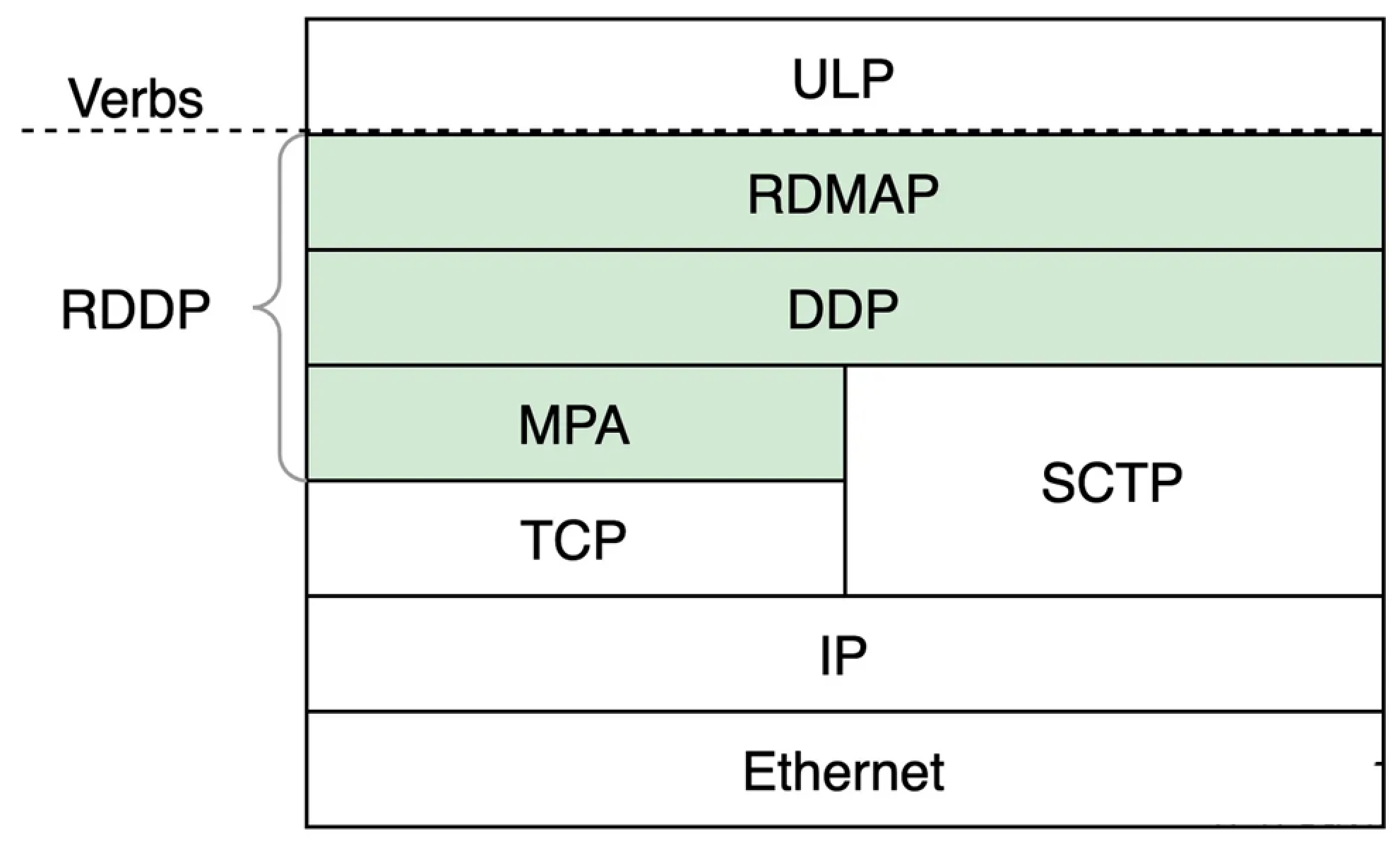
- RDMAP(Remote Direct Memory Access Protocol):RDMAP是iWARP协议栈中最靠近用户的一层,主要功能是为上层用户提供RDMA语义,支撑它们的Send/RDMA Read/RDMA Write等各种类型的请求。RDMAP依赖于下层的DDP提供的零拷贝功能来实现对应的用户请求。
- DDP(Data Placement Protocol):DDP是iWARP的核心,负责在传输层协议之上实现零拷贝的功能。DDP的报文中包含有描述内存区域的信息,硬件可以直接根据DDP报文中的控制信息,通过DMA搬移DDP报文中的数据到内存中的目的地。
- MPA(Marker Protocol data unit Aligned framing):MPA这一层负责在发送端按照一定的算法在TCP流中加入控制信息,从而使得接收端可以按照算法识别出流中的DDP消息的分界。实际上完成的是将DDP适配TCP的工作。当DDP的下层是SCTP协议时就不需要MPA这一层了,因为SCTP可以识别出上层协议的分界。
iWARP 从以下几个方面降低了主机侧网络负载:
- TCP/IP 处理流程从 CPU 卸载到 RDMA 网卡处理,降低了 CPU 负载。
- 消除内存拷贝:应用程序可以直接将数据传输到对端应用程序内存中,显著降低 CPU 负载。
- 减少应用程序上、下文切换:应用程序可以绕过操作系统,直接在用户空间对 RDMA 网卡下发命令,降低了开销,显著降低了应用程序上、下文切换造成的延迟。
由于 TCP 协议能够提供流量控制和拥塞管理,因此 iWARP 不需要以太网支持无损传输,仅通过普通以太网交换机和 iWARP 网卡即可实现,因此能够在广域网上应用,具有较好的扩展性。
除了Infiniband技术由NVIDIA一家独大之外,iWARP和RoCEv2阵营中都有多个厂商。虽然RoCEv2的存在感比较高,而且市场占有率也更高,但是iWARP也并非完全被RoCE v2碾压。从两者中做选择时,要充分考虑自己的网络环境和业务场景等因素。如果网络规模较小,对时延敏感,那么更建议选择RoCE v2;如果网络规模大、注重网络的可扩展性,或者对时延不敏感(Mellanox和Marvell给出的数据,纯RDMA业务场景下,大包时延差距在20%以上甚至更多),那么更建议选择iWARP。
| iWARP | RoCE v2 | |
|---|---|---|
| 标准组织 | IETF | IBTA |
| 规范 | RFC 5040~5045、6580、6581、7306 | IB Architecture Specification |
| 传输层协议 | TCP | UDP |
| 总协议层数 | 7 | 5 |
| 主要厂商 | Intel、Chelsio、Marvell | NVIDIA(Mellanox)、Broadcom、华为、Marvell |
| 网络环境 | 有损/无损 | 无损 |
| 诞生时间 | 2003年 | 2014年 |
| 重传机制 | 选择性重传 | Go back N |
| 拥塞控制算法 | TCP、DCTCP、TIMELY等 | DCQCN、LDCP、TIMELY等 |
| 支持服务类型 | RC | RC、UD、XRC、UC等 |
| 支持建链类型 | CM | Socket、CM |
| 通信时延 | 大 | 小 |
| 可扩展性 | 强 | 弱 |
| 部署难度 | 低 | 高 |
| 实现复杂度 | 高 | 低 |
| 灵活性 | 低 | 高 |
评论