NVIDIA Spectrum-X: 基于Ethernet的AI加速网络平台
人工智能工作负载的特点是少量的任务处理大量的GPU之间的数据传输,尾延迟会对整体应用性能产生显著影响。使用传统的网络路由机制来处理这种流量模式可能导致GPU性能不一致和人工智能工作负载低利用率。
NVIDIA Spectrum-X RoCE动态路由是一种精细化负载均衡技术,通过动态调整RDMA数据路由以避免拥塞,结合BlueField 3的DDP技术,提供最佳负载均衡和实现更高效的数据带宽。
Spectrum-X 网络平台概述
NVIDIA® Spectrum™-X 网络平台是第一个专为提高Ethernet-based AI云的性能和效率而设计的以太网平台。这项突破性技术在类似LLM的大规模AI工作负载中,提升了1.7倍AI性能、能效,以及保证在多租户环境中的一致、可预测性。
Spectrum-X基于Spectrum-4以太网交换机与NVIDIA BlueField®-3 DPU网卡构建,针对AI工作负载进行了端到端优化。
Spectrum-X 关键技术
为支持和加速AI工作负载,Spectrum-X 从DPUs到交换机、电缆/光学器件、网络和加速软件,进行了一系列优化,包括:
-
Spectrum-4上的NVIDIA RoCE自适应路由
-
BlueField-3上的NVIDIA直接数据放置(Direct Data Placement, DDP)
-
Spectrum-4和BlueField-3上的NVIDIA RoCE拥塞控制
-
NVIDIA AI加速软件
-
端到端AI网络可见性
Spectrum-X关键优势
- 提高AI云性能:Spectrum-X将AI云性能提升1.7倍。
- 标准以太网连接:Spectrum-X完全符合以太网的标准,并与基于以太网的技术堆栈完全兼容。
- 提高能源效率:通过提高性能,Spectrum-X为更节能的AI环境做出贡献。
- 增强的多租户保护:在多租户环境中进行性能隔离,确保每个租户的工作负载表现最佳、并始终如一,推动提高客户满意度和服务质量。
- 更好的AI网络可见性:对AI云中运行的流量进行可见性监控,可以识别性能瓶颈,是现代自动化网络验证解决方案的关键组成部分。
- 更高的AI可扩展性:支持以一跳的方式扩展到128个400G端口,或者以两级spine拓扑结构扩展到8K个端口,同时保持高性能水平,支持AI云的扩展。
- 更快的网络设置:高级网络功能自动化的端到端配置,完全针对AI工作负载进行优化。
Spectrum-4以太网交换机
Spectrum-4交换机基于51.2Tbps的ASIC构建,支持单个2U交换机中最多128个400G以太网端口。Spectrum-4是第一个为AI工作负载设计的Ethernet的交换机。针对AI,对RoCE进行了扩展:
-
RoCE自适应路由
-
RoCE性能隔离
-
在大规模标准以太网上的有效带宽提升
-
低延迟、低抖动和短的尾延迟

图2. NVIDIA Spectrum-4 400 Gigabit以太网交换机
BlueField-3 DPU
NVIDIA BlueField-3 DPU是第三代数据中心基础设施芯片,使组织能够构建从云到核心数据中心到边缘的软件定义的、硬件加速的IT基础设施。通过400Gb/s以太网网络连接,BlueField-3 DPU可以卸载、加速和隔离软件定义的网络、存储、安全和管理功能,从而显著提高数据中心的性能、效率和安全性。BlueField-3为由Spectrum-X驱动的云AI数据中心中的南北和东西流量,提供多租户、安全性能力。

图3. NVIDIA BlueField-3 400Gb/s以太网DPU
BlueField-3专为AI加速而构建,集成用于AI的all-to-all引擎、NVIDIA GPUDirect和NVIDIA Magnum IO GPUDirect Storage加速技术。
此外,它还具有特殊的网络接口模式(NIC)模式,利用本地内存加速大型AI云。这些云包含大量的队列对,可以在本地地址而不是使用系统内存进行访问。
最后,它包括NVIDIA Direct Data Placement (DDP)技术来增强RoCE自适应路由。
NVIDIA端到端物理层(PHY)
Spectrum-X是唯一一个建立在相同100G SerDes通道上的以太网网络平台,从交换机到DPU到GPU都采用了NVIDIA的SerDes技术。
NVIDIA的SerDes确保出色的信号完整性和最低的误码率(BER),大大降低了AI云的功耗。这种强大的SerDes技术,结合NVIDIA的Hopper GPUs、Spectrum-4、BlueField-3和Quantum InfiniBand产品组合,实现了功耗效率和性能的完美平衡。
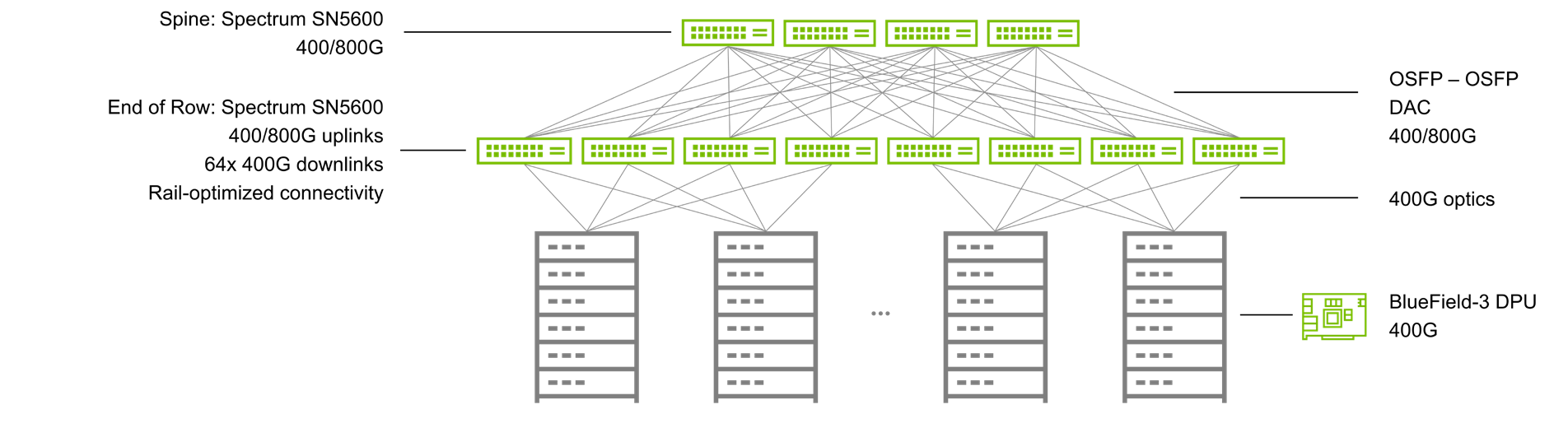
图4. 典型的Spectrum-X网络拓扑
SerDes技术在现代数据传输中起着重要作用,它能将并行数据转换为串行数据,反之亦然。
在网络或系统的所有网络设备和组件中统一使用SerDes技术带来了许多优势:
-
成本和功耗效率:NVIDIA Spectrum-X使用的SerDes经过优化,具有很高的功耗效率,并且不需要网络中的gearboxes,gearboxes用于桥接不同的数据速率。使用gearboxes不仅会增加数据路径的复杂性,还会增加额外的成本和功耗。消除这些gearboxes的需求减少了初始投资以及与功耗和冷却相关的运营成本。
-
系统设计效率:在数据中心基础设施中统一使用最佳SerDes技术可以提供更好的信号完整性,减少了系统组件的需求,简化了系统设计。同时,统一使用相同的SerDes技术还使操作更简单,提高了可用性。
NVIDIA加速软件
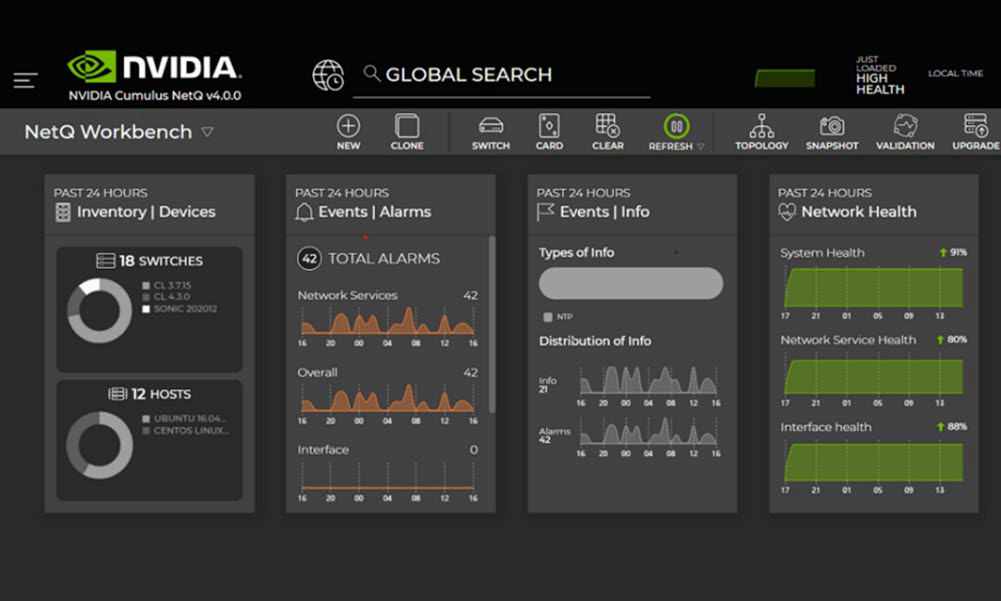
NetQ
NVIDIA NetQ是一个高度可伸缩的网络运维工具集,用于实时AI网络可见性、故障排除和验证。NetQ利用NVIDIA交换机遥测数据和NVIDIA DOCA遥测来提供有关交换机和DPU健康状况的洞察,将网络集成到组织的MLOps系统中。
此外,NetQ流量遥测可以映射跨交换机端口和RoCE队列的流路径和行为,以分析特定应用程序的流动情况。
NetQ对数据包进行采样、分析和报告每条流动路径上的延迟(最大值、最小值和平均值)和缓冲区占用详细信息。NetQ GUI报告了所有可能的路径、每个路径的详细信息和流动行为。将telementry的遥测与流量遥测相结合,有助于网络运营人员主动识别导致服务器和应用程序问题的根本原因。
Spectrum SDK
NVIDIA以太网交换机软件开发工具包(SDK)提供了实施交换和路由功能的灵活性,具有不影响包速率、带宽或延迟性能的复杂可编程性。借助SDK,服务器和网络OEM以及网络操作系统(NOS)供应商可以利用以太网交换机系列集成电路(IC)的先进网络功能,构建灵活、创新和成本优化的交换解决方案。
NVIDIA DOCA
NVIDIA DOCA是释放NVIDIA BlueField DPU的潜力、卸载、加速和隔离数据中心工作负载的关键。借助DOCA,开发人员可以通过创建软件定义、云原生、DPU加速的服务与零信任保护,以应对现代数据中心日益增长的性能和安全需求。
NVIDIA Spectrum-X主要特点
1. NVIDIA RoCE动态路由的工作原理
RoCE动态路由由Spectrum-4交换机和BlueField-3 DPU以端到端的方式工作:
- Spectrum-4交换机负责选择每个数据包基于最低拥塞端口,均匀分配数据传输。当同一流的不同数据包通过网络的不同路径传输时,它们可能以无序的方式到达目的地。
- BlueField-3 DPU在RoCE传输层处理无序数据,以提供连续的数据透明给应用程序。
Spectrum-4根据出口队列的负载评估拥塞情况,以确保所有端口的利用率平衡。对于每个网络数据包,交换机选择出口队列中负载最低的端口。Spectrum-4还会接收来自相邻交换机的状态通知,这也可以影响转发决策。评估中涉及的队列与它们对应的流量类别匹配。因此,Spectrum-X在超大规模系统和高负载场景下可以实现高达95%的有效带宽。
2. NVIDIA RoCE动态路由与NVIDIA直接数据放置技术
下面,以数据包级别的示例演示AI流在Spectrum-X网络中的移动过程。
它显示了Spectrum-4交换机上的RoCE动态路由与BlueField DPU上的NVIDIA直接数据放置(DDP)技术之间的协同过程。
步骤1:数据起源于图表左边的服务器或GPU内存,目的地是右边的服务器。
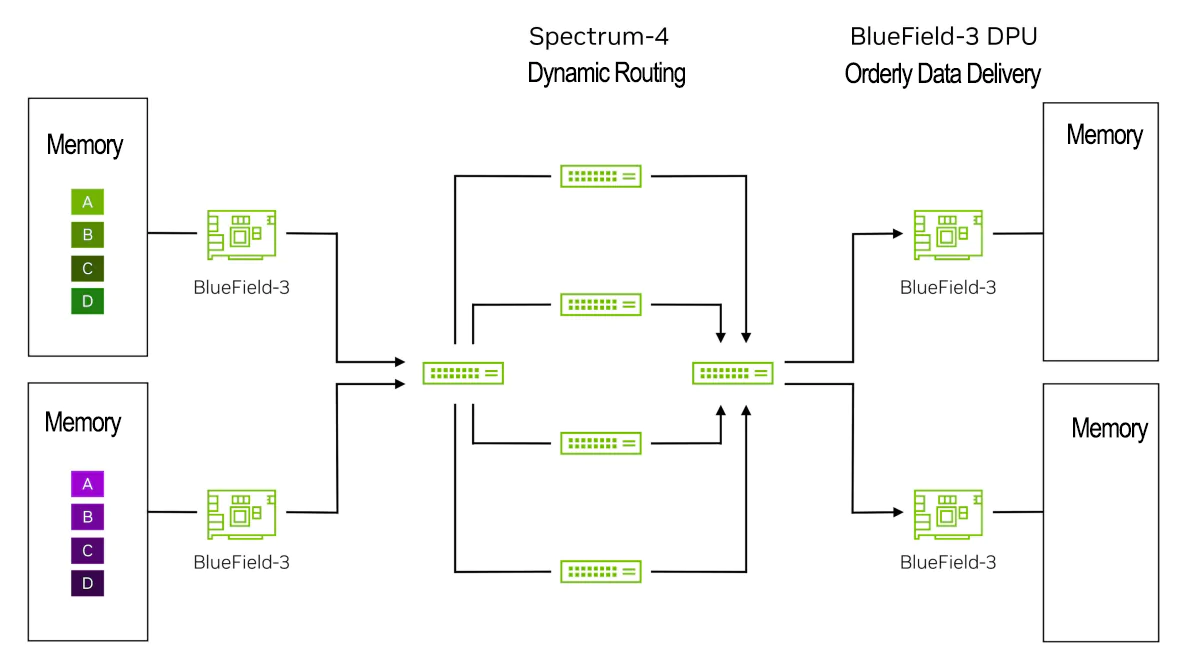
步骤2:BlueField-3 DPU将数据封装网络数据包,并将其发送给第一个Spectrum-4 leaf交换机,同时标记这些数据包以确保交换机对这些报文进行RoCE动态路由。
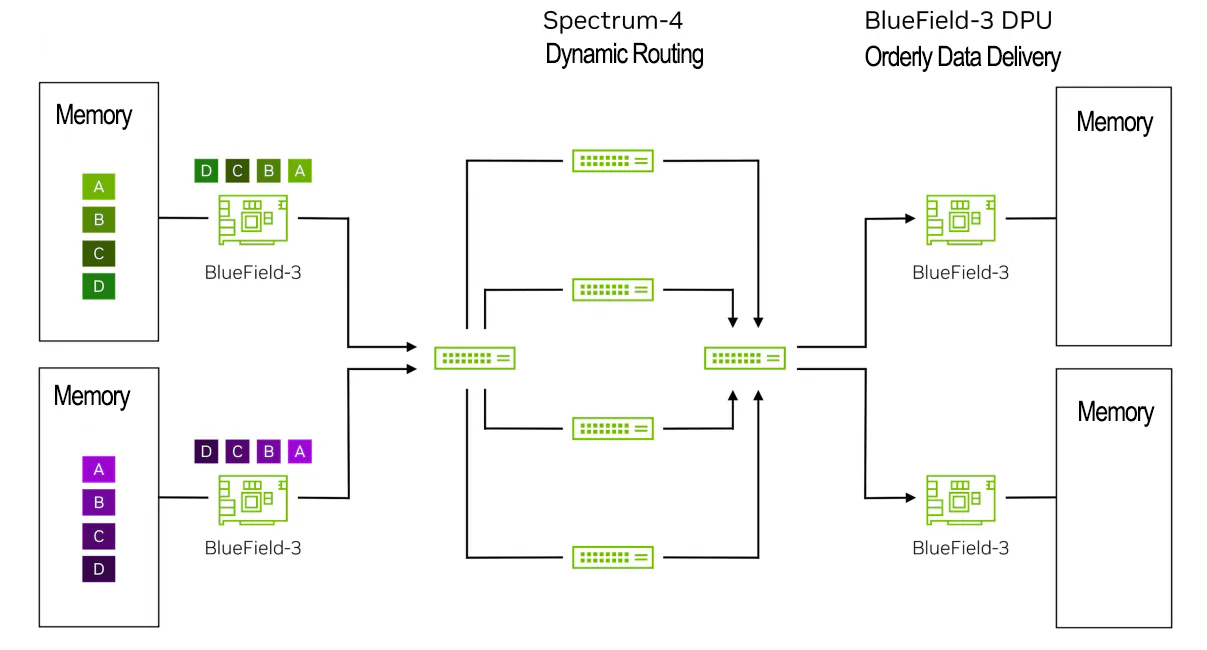
步骤3:左侧的Spectrum-4 leaf交换机应用RoCE动态路由来负载均衡来自绿色和紫色流的数据包,将每个流的数据包发送到多个骨干交换机。这将有效带宽从标准以太网的60%提高至Spectrum-X的95%(1.6倍)。
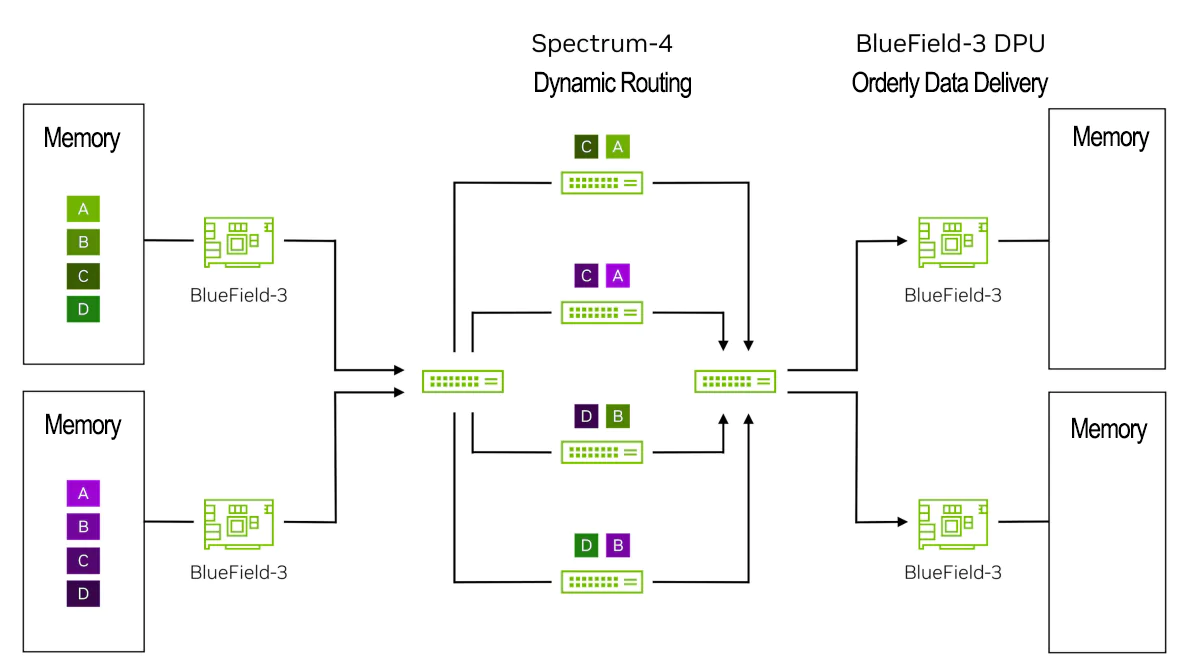
步骤4:这些数据包在到达右侧的BlueField-3 DPU时可能无序。
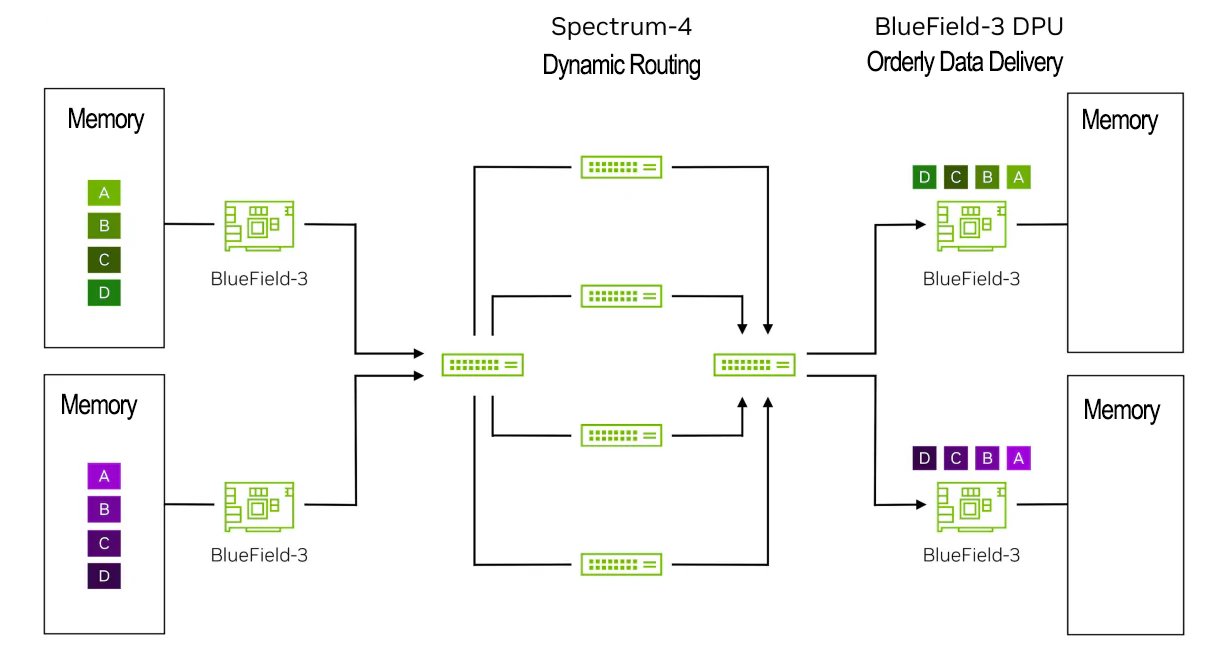
步骤5:右侧的BlueField-3 DPU使用NVIDIA直接数据放置(DDP)技术将数据按正确顺序放置在主机/GPU内存中。
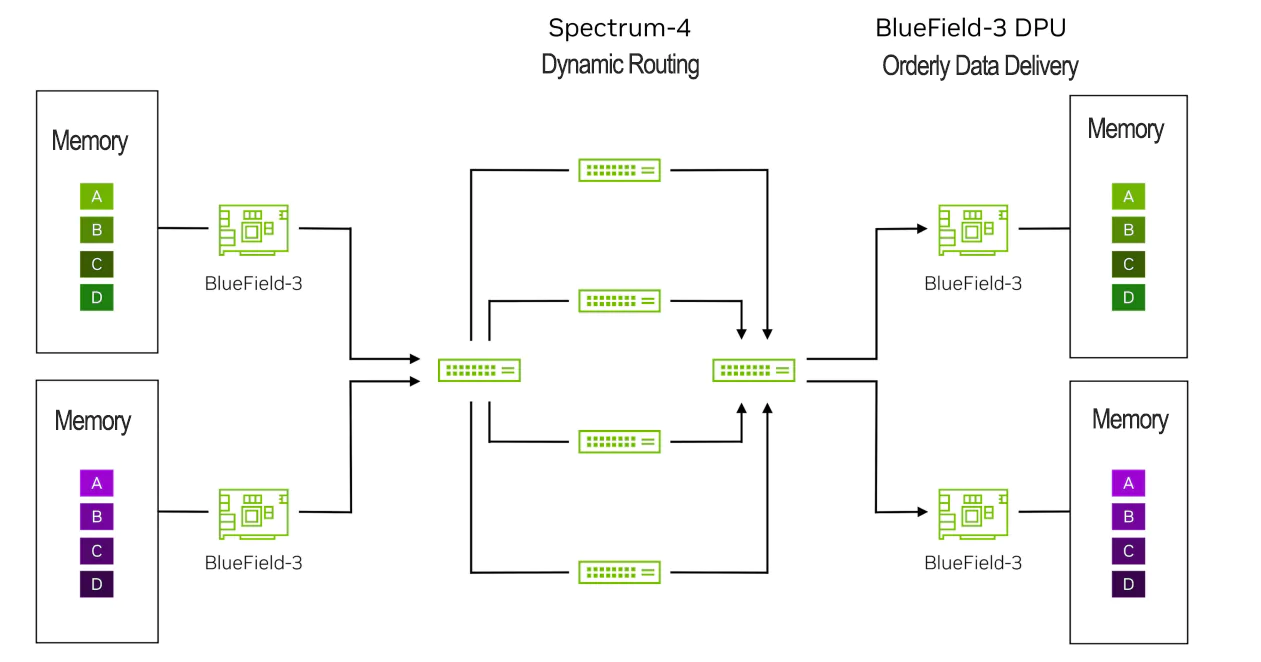
RoCE动态路由的结果
为了验证RoCE动态路由的有效性,我们使用RDMA写测试程序进行了初始测试。在测试中,我们将主机分为若干对,每对主机彼此发送大量RDMA写数据流进行持续一段时间。
RoCE动态路由可以减少流完成时间。
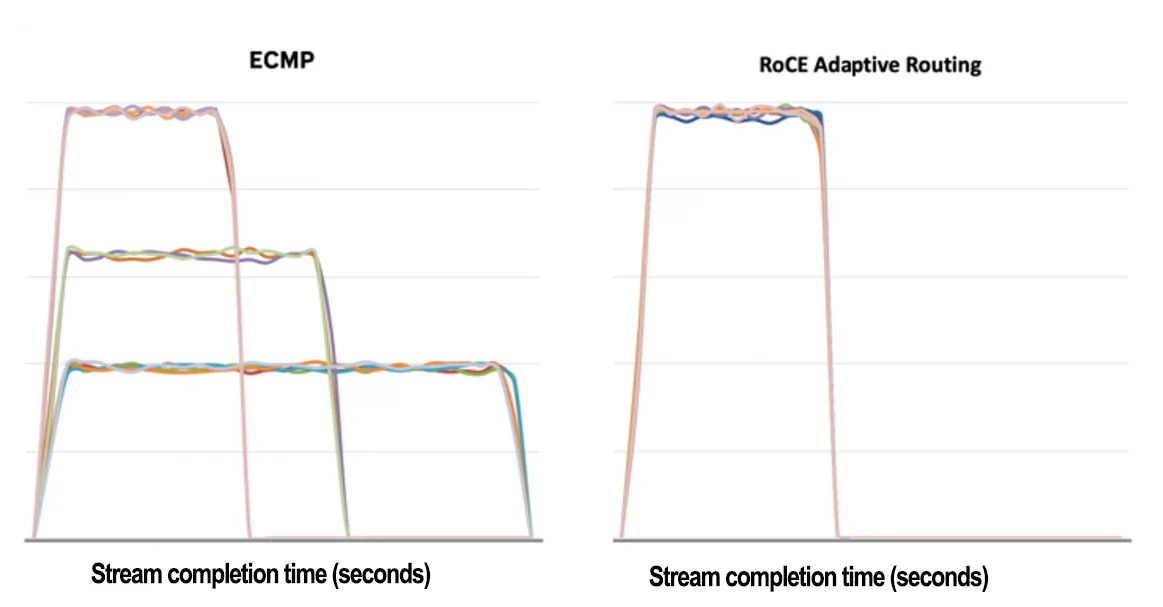
如上图所示,基于哈希的静态转发机制导致上行端口发生冲突,导致通信完成时间增加、带宽减少和流之间的公平性降低。切换到动态路由解决了所有这些问题。
在ECMP图中,一些流展现出相同的带宽和完成时间,而其他流则经历了冲突,导致较长的完成时间和较低的带宽。具体来说,在ECMP场景中,一些流的最佳完成时间T为13秒,而最慢的流完成所需时间为31秒,约为理想时间T的2.5倍。在RoCE动态路由图中,所有流几乎在相同的时间完成,具有类似的峰值带宽。
RoCE动态路由用于AI工作负载
为了进一步评估RoCE工作负载中动态路由的性能,我们在一个由32台服务器组成的测试平台上进行了常见的AI基准测试,利用了由四台NVIDIA Spectrum交换机构建的两层leaf-spine网络拓扑。这些基准测试评估了在分布式AI训练工作负载中常见的集合操作和网络流量模式,例如all-to-all流量和all-reduce集合操作。
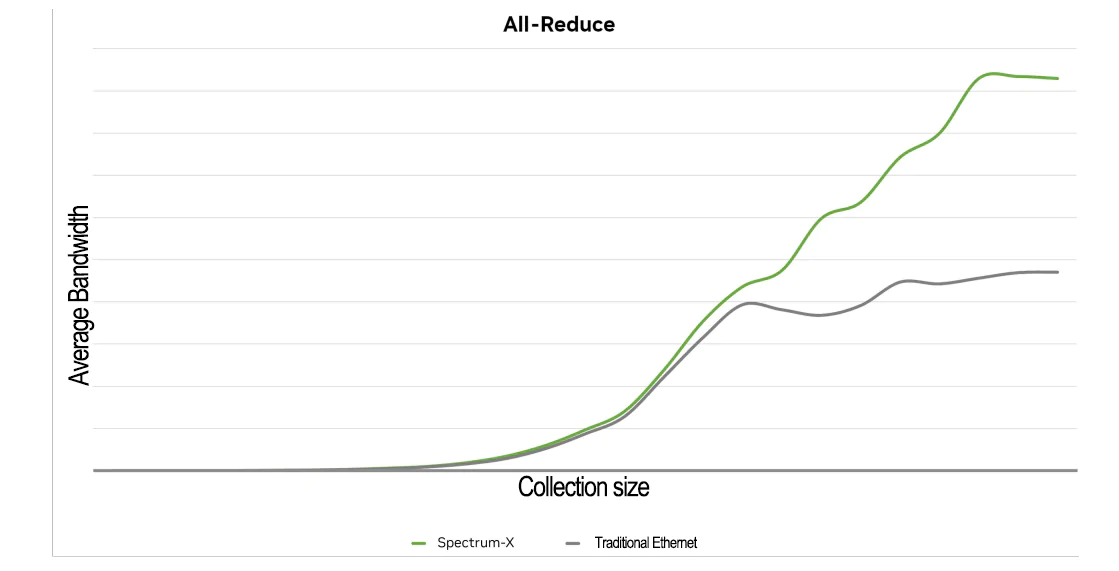
RoCE动态路由增强AI all-reduce
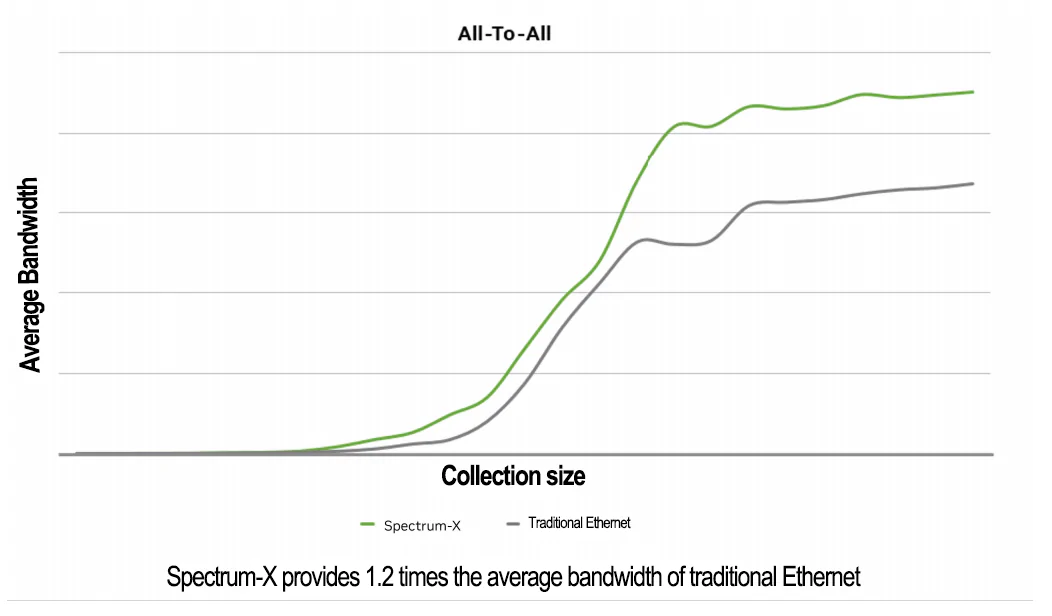
RoCE动态路由增强AI all-to-all
RoCE动态路由总结
在许多情况下,基于哈希的ECMP流路由可能会导致高度拥塞和不稳定的流完成时间,从而导致应用程序性能下降。Spectrum-X RoCE动态路由解决了这个问题。该技术提高了实际网络吞吐量(goodput),同时最大限度地减少了流完成时间的不稳定性,从而提升了应用性能。
通过将RoCE动态路由与BlueField-3 DPU上的NVIDIA Direct Data Placement(DDP)技术结合使用,可以实现对应用程序的透明支持。
使用NVIDIA RoCE拥塞控制实现性能隔离
由于网络拥塞,在AI云系统中同时运行的应用程序可能会出现性能降低和不稳定的运行时间。这种拥塞可能是由应用程序本身的网络流量或其他应用程序的后台网络流量引起的。造成这种拥塞的主要原因是多对一拥塞,即存在多个数据发送者和一个数据接收者。
RoCE的动态路由无法解决这种拥塞问题。事实上,这种问题需要对每个端点进行流量测量。Spectrum-X RoCE拥塞控制是一种端到端技术,其中Spectrum-4交换机提供网络遥测信息以表征网络中的实时拥塞情况。这些遥测信息由BlueField-3 DPU处理,它管理和控制数据发送者的数据注入速率,以最大化共享网络的效率。如果没有拥塞控制,多对一场景可能会导致网络背压、拥塞扩散甚至丢包,严重降低网络和应用程序的性能。
拥塞控制过程中,BlueField-3 DPU执行拥塞控制算法,能够每秒处理数百万次拥塞控制事件,在微秒级别做出快速、细粒度的速率决策。Spectrum-4交换机的带内遥测为准确的拥塞估计提供队列信息,并提供端口利用率指标以实现快速恢复。NVIDIA的拥塞控制允许遥测数据绕过拥塞流的队列延迟,同时仍然提供准确的并发遥测信息,大大减少了拥塞检测和反应时间。
以下示例演示了网络经历了多对一拥塞,以及Spectrum-X如何利用流量计量和带内遥测进行RoCE拥塞控制。
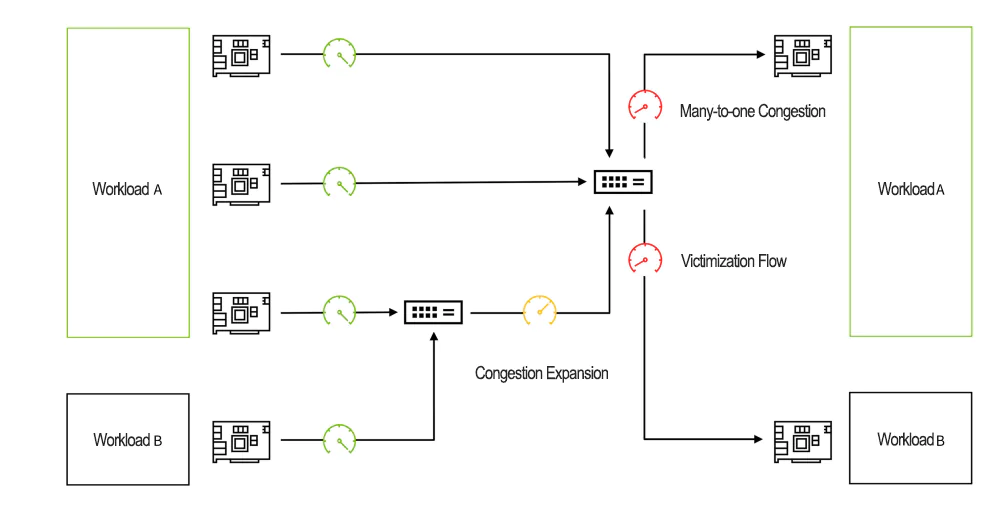
网络拥塞导致受干扰流
这个图显示了由网络拥塞引起的受干扰流。四个源DPUs正在向两个目标DPUs传输数据。源1、2、3将数据发送到目标1,每个接收器利用可用链路带宽的三分之一。源4通过与源3共享的leaf交换机向目标2发送数据,导致接收端获得可用链路带宽的三分之二。
如果没有拥塞控制,源1、2、3会导致3比1的拥塞,因为它们都向目标1发送数据。这种拥塞会导致从目标1传播到与源1和2连接的leaf交换机的背压。源4成为受干扰流,其到达目标2的吞吐量降低到可用带宽的33%(预期性能的50%)。这对依赖于平均和最坏情况性能的AI应用性能产生了不利影响。
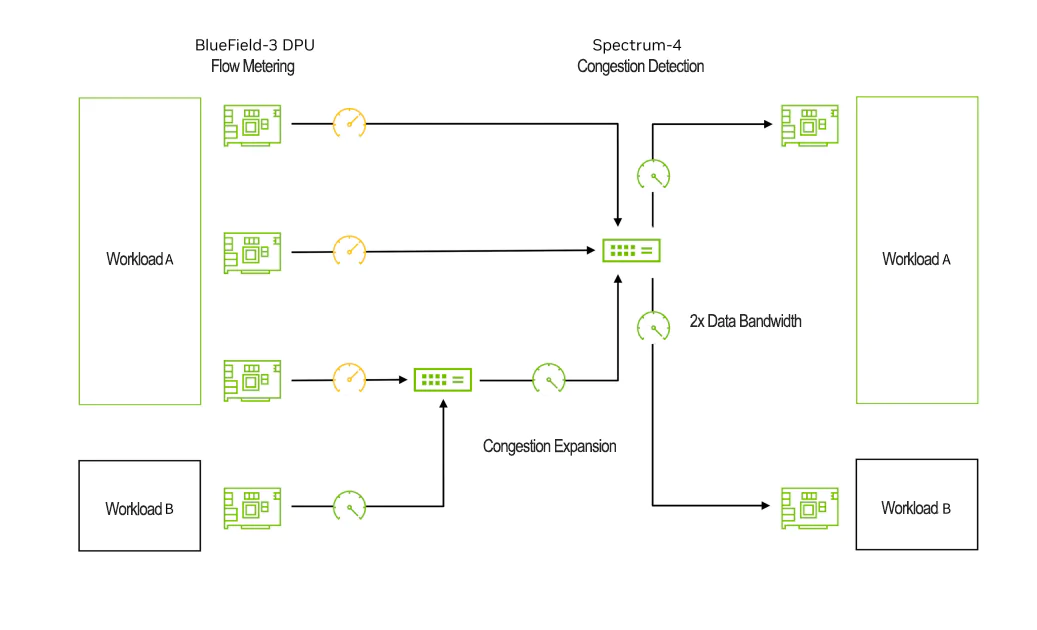
Spectrum-X通过流量计量和拥塞遥测解决拥塞问题
该图示展示了Spectrum-X如何解决图14中的拥塞问题。它展示了同样的测试环境:四个源DPUs向两个目标DPUs传输数据。在这种情况下,源1、2和3上的流量测量,防止leaf交换机出现拥塞。这消除了影响源4的背压,使其能够达到预期的三分之二的可用带宽。此外,Spectrum-4利用由What Just Happened生成的带内遥测信息动态重新分配流路径和队列行为。
RoCE性能隔离
AI云基础设施需要支持大量用户(租户)和并行应用程序或工作流。这些用户和应用程序会竞争基础设施的共享资源,例如网络,这可能影响彼此的性能。
此外,为了优化NVIDIA集体通信库(NCCL)的AI网络性能,需要在云中同时运行的所有工作负载之间进行协调和同步。云的传统优势,如弹性和高可用性,对AI应用的影响有限,而性能下降是一个更重要的全局问题。
Spectrum-X平台包括多个机制,当这些机制结合起来时,可以实现性能隔离。它确保一个工作负载不会影响另一个工作负载的性能。这些服务质量机制保证任何工作负载都不会引起网络拥塞,从而影响其他工作负载的数据传输。
通过RoCE动态路由的帮助,实现了细粒度数据路径平衡,避免了通过叶子交换机和脊交换机传递的数据流冲突,从而实现了性能隔离。通过流量测量和遥测启用的RoCE拥塞控制,可以防止多对一流量引起的受害流,进一步增强性能隔离。
此外,Spectrum-4交换机采用全局共享缓冲区设计,以促进性能隔离。共享缓冲区为不同大小的流提供带宽公平性,保护工作负载免受“有噪音的邻居”流的影响,并在有多个流目标相同目的端口的场景下更好地吸收微突发传输。
参考
- NVIdia Spectrum-X Network Platform Architecture white paper
评论